Cinegy Multiviewer 21 – Go Further With GPU
Reading time ~11 minutes
This post is a slightly amended version of the presentation that Yaroslav Korniets gave during Cinegy’s Technical Conference 2021, which was live-streamed on March 25th and is now available to view as a recording.
NVIDIA GPU Acceleration Overview
Graphics chips started as fixed-function graphics pipelines. Over the years, these graphics chips became increasingly programmable, which led NVIDIA to introduce the first Graphics Processing Unit.

The biggest constraint in using the GPUs for general purposes was that they required the use of graphics programming languages like OpenGL and CG to program the GPU.

NVIDIA realized the potential of bringing this performance to the wider community and invested in modifying the GPU to make it fully programmable for scientific applications. Plus, it added support for high-level languages like C, C++, and Fortran. This led to the CUDA parallel computing platform for the GPU.
What’s Inside NVIDIA GPU?

Whilst the CPU is comprised of cores designed for sequential serial processing, the GPU is designed with a parallel architecture, consisting of more efficient yet smaller cores that can easily handle multiple tasks in parallel. Simpler computing cores allow GPUs to pack many more cores into a chip than a general-purpose CPU. Additionally, GPU architectures have specialized their memory architecture to support high-speed data streaming for image processing, important for broadcasting.

NVIDIA GPUs contain one or more hardware-based decoder and encoder chips (separate from the CUDA cores), which provide fully-accelerated video decoding and encoding for several popular codecs. GPU hardware accelerator engines for video decoding, NVDEC, and video encoding, NVENC, support faster-than-real-time video processing, which makes them suitable for transcoding applications, in addition to video playback.
Cinegy’s GPU Journey
Cinegy Air version 12 moved the compositing stage of the playout pipeline to optionally reside within the GPU, which had great benefits for customers who wanted to use our integrated branding system for adding graphics to the output or were using the very convenient and efficient NVIDIA NVENC H.264/H.265 encoding blocks.
As people pushed the boundaries of the engine, the computation overhead of taking source material decoded within the CPU became a limiting factor. To reach the dream of 8K60 at 10-bit, there was a need to cure this. As a result, a way was created to connect the input stage of the media layer to the compositing stage without moving over the CPU at all.
Cinegy went further with integrating an excellent GPU pipeline into Cinegy Capture, to both decode the input IP feeds and encode the output files, and Cinegy Convert, which uses the GPU pipeline for media transcoding.
GPU acceleration made migration to cloud platforms smooth and seamless, and today, the complete media production workflow can be run from the cloud.
Cinegy Multiviewer is not an exception – it is using NVDEC to decode IP feeds as well as NVENC to encode the IP outputs ever since version 11. But recently, significant improvements have been made in Cinegy Multiviewer’s GPU pipeline.
The Challenge

We challenged ourselves to build a high-density Cinegy Multiviewer server, able to decode and display an impressive one hundred full HD feeds.
For this, 4x NVIDIA Quadro RTX4000 cards in a 64-core AMD Threadripper workstation were used. Cinegy components were used to generate and send one hundred of those feeds over a 10 Gb link to this beast of a machine.
What seemed odd, that even with the stunning performance of 4 RTX cards, the CPU load during this experiment turned out to be suspiciously high, while at the same time the GPU’s load seemed to be clearly slacking off.
So, where could resource utilization be improved?
We were confident about our NVENC and NVDEC workflow, so it was ruled out as the potential bottleneck and the attention was focused on another component, key to Cinegy Multiviewer’s performance – scaling.

During the video frame processing required for scaling, the GPU would decode an uncompressed video frame of 4 Mb of data (for Full HD). This data goes through a number of copying cycles from GPU to RAM, then to the CPU, just to be passed back to the CUDA cores of our GPU’s main chip for processing.

The main idea around improvements was about reducing the amount of these data copying operations and concentrating data processing in Cinegy Multiviewer’s master GPU pipeline.
The results of the tests on the next pictures will illustrate just how brilliantly Cinegy coped with the task of optimization.

In the tests, the same software setup was used on three different testing kits. Cinegy Multiviewer 15 was used as a baseline. It was connected to the Grafana-based telemetry portal with the help of the Metricbeat application.
The idea of tests was pretty simple – to load test Cinegy Multiviewer servers with IP feeds to operate at hardware capacity using GPU decoding, take the measurements, repeat the tests with a yet unreleased Cinegy Multiviewer 21, and compare the results.
TestKit#1 – The Regular

A server with a 7-year-old Intel Xeon chip and an NVIDIA Quadro P2200 board was chosen for the tests, almost matching the specifications from Cinegy system recommendations.
These 24 were fed to the input of Cinegy Multiviewer 15 as multicast RTP over a 10 Gigabit LAN. All the streams were set to be decoded by a GPU.
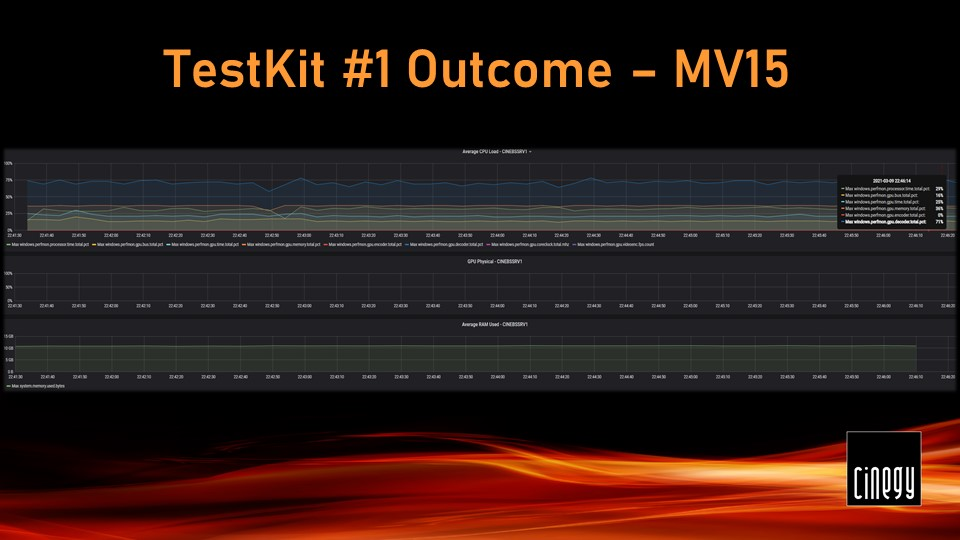
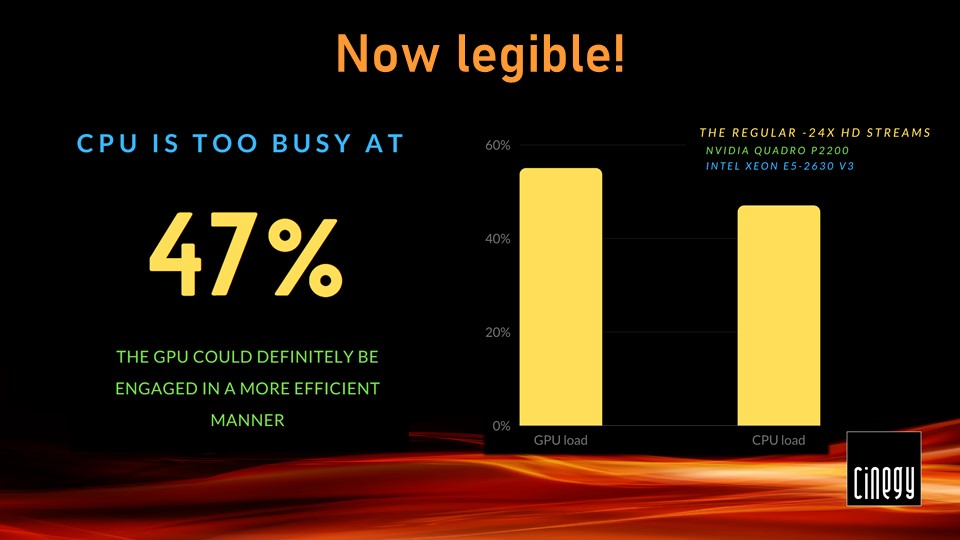
The CPU load in this test fluctuated between 45-50%, whilst the GPU was operating at 55% load, most of which is the video engine load attributed to NVDEC performance. A quick look at GPU-Z readings proved that the main chip doing scaling was barely engaged.
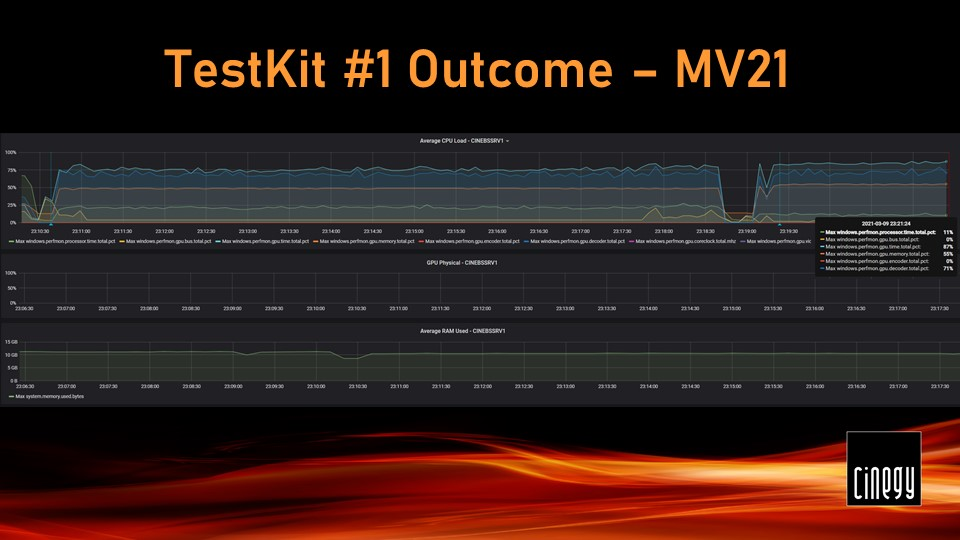
Next step was upgrading Cinegy Multiviewer to a development version 21, which includes changes to scaling, and then the CPU load significantly decreased! CPU was running at 25% to 30%, while the GPU was pretty busy at 75% load.
Having had another look at the GPU-Z sensors, it was noted that the general GPU load had increased, while the Studio engine stayed pretty much where it was in Cinegy Multiviewer 15. The main chip’s engagement is clear evidence that the optimization is working. CPU load decreased by half and an extra 20% of GPU utilization, which sounds good for starters!
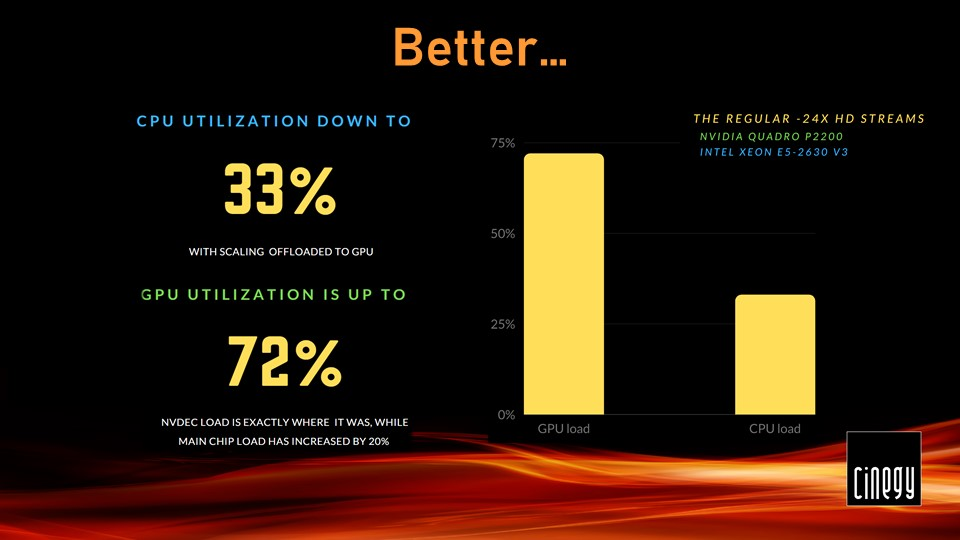
However, these results do not look as impressive on pure hardware: Cinegy Multiviewer 15 scaling simply doesn’t eat out as much CPU on this setup.
What’s going to happen if we try the same on virtual machines in the cloud?
TestKit#2 – The Cloud-one

An AWS G4 instance was chosen. Equipped with a Tesla T4 GPU and a 24-core Xeon Platinum CPU, they offer great performance for a relatively cost-effective price. Additionally, it literally takes a couple of minutes to get an EC2 instance ready for production. Check out our YouTube video from last summer, where we spent literally 10 minutes using Terraform scripts automation to launch 150 playout channels in the AWS environment, monitored by Cinegy Multiviewer 15.
Similar to the previous test, this one started with Cinegy Multiviewer 15 and 12 HD H.264 SRT streams were fed to it, delivered over the public Internet.
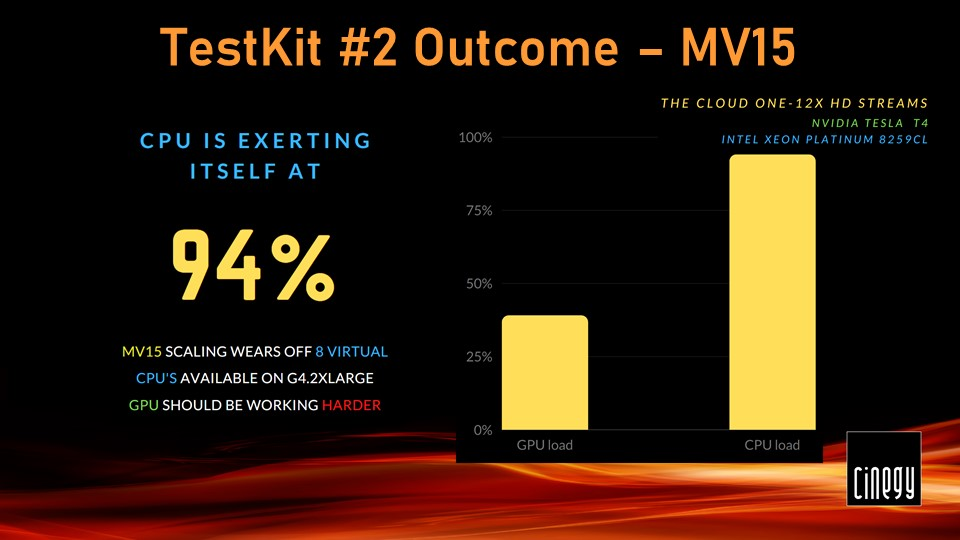
Cinegy Multiviewer 15 makes that CPU work really hard at 94%, while the NVIDIA T4 was slacking off at 40% load, and even though decoding SRT streams eventually produces more CPU load. It is worth being reminded – Cinegy Multiviewer was set to use a GPU to decode each of those input streams.
An upgrade to Cinegy Multiviewer 21 introduced quite a dramatic shift in performance.
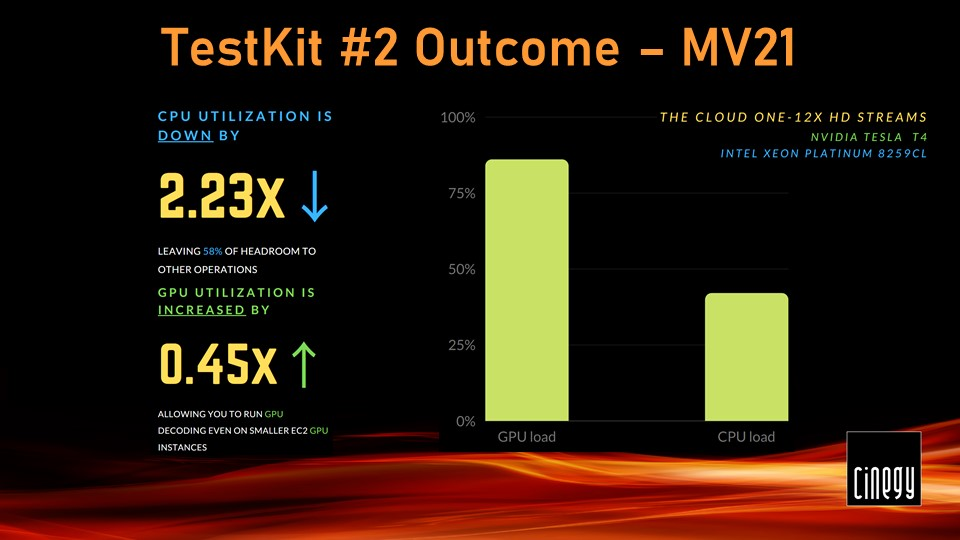
CPU utilization went down to just 42%, while the GPU started working at 86%. It pretty much flipped the processing from CPU to GPU.
This EC2 test kit is a good indication of how an entry-level GPU instance can be a great and cost-effective choice for cloud monitoring. Running all decoding for 12 streams on CPU only at a comfortable load would require at least a G4.4xlarge instance at £1.55/hour.

GPU-offloaded decoding for the same number of streams is already an option for roughly half of that price with G4.2xlarge instances, and with the optimizations introduced, it leaves even more CPU headroom to neatly carry out other operations. If you don’t care about headroom, you could potentially get away with a G4.xlarge at even lower rates.
TestKit#3 – The Beast – 100 feeds
Let’s return now to the challenge of monitoring 100 HD channels in a single box.

Remember, an amazing 64-core AMD Threadripper with 4 NVIDIA RTX cards was used. Unlike the old P2200, which only has one NVDEC chip, each of these cards offers 2 NVDEC chips, almost twice as many CUDA cores, and an extra 3 GB of memory, providing a level of density required to handle that many streams in parallel.

So, 100 5MB HD, H.264 feeds were streamed to the Cinegy Multiviewer 15, letting each of the cards decode 25 streams. The CPU load was at 15% – whilst this seems low, this is definitely too much for a 64-core Threadripper with GPU offloading enabled.
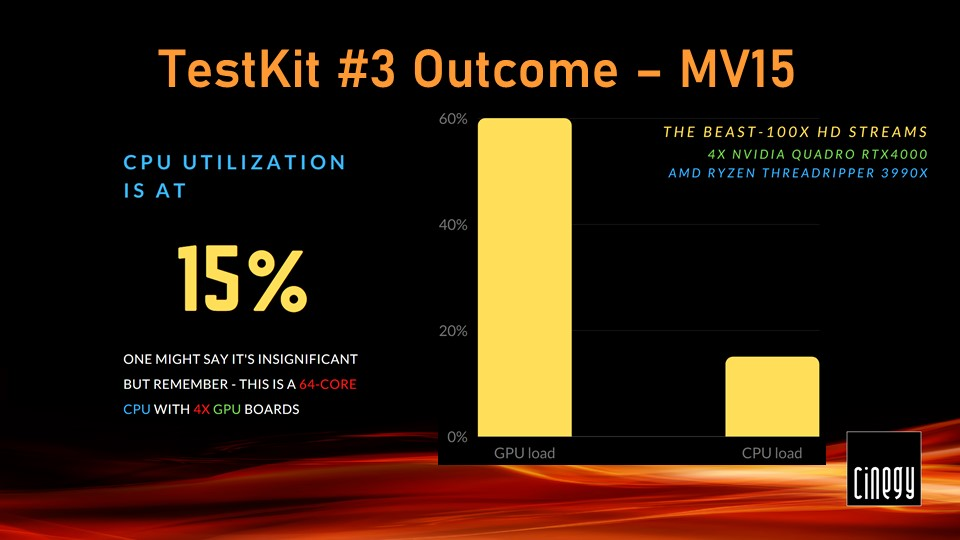
At the same time, the GPUs, which were supposed to be busy with some heavy lifting, were taking it easy, operating at 60%. The tiles on the Cinegy Multiviewer mosaic did not look smooth either, and the quality could be improved.
Let’s see whether any improvement with the same setup running Cinegy Multiviewer 21 can be spotted. The CPU load dropped to 6% while the GPUs started working way harder at 80-90% each.
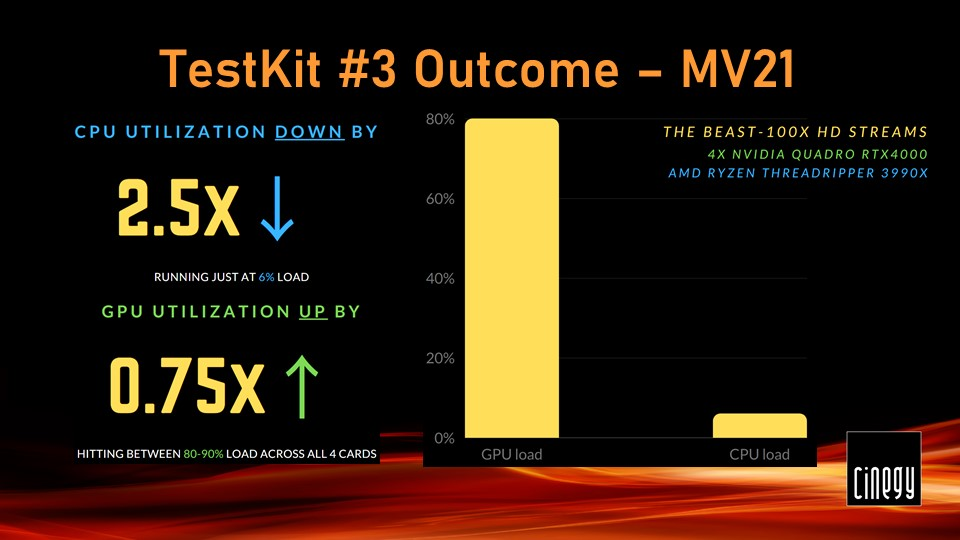
This resulted in Cinegy Multiviewer pipes having pristine quality and no jitter whatsoever.
Challenge completed!
Power Consumption
Having such an extraordinary machine at our disposal, it is interesting to know how much power this "beast" actually consumes. Let’s check whether the optimization in Cinegy Multiviewer has any impact on its energy efficiency. Having heard a lot about RTX GPUs being hungrier for power than the CPUs, we decided to try and check whether the new Cinegy Multiviewer can bust that myth. A 64-core AMD Threadripper chip seems to be a great rival for multiple GPUs, so the same challenge, but this time the focus will be on power consumption rather than the CPU and GPU load.
A simple approach with a watt-per-hour wall socket meter was used. Filtering the noise (like the operating system, background processes, etc.) was skipped, and focus was on measuring general consumption, assuming that 90% of power draw would be caused by CPU/GPU work anyway.
At the start, 50 HD feeds were decoded in Cinegy Multiviewer 21 by CPU. That is the number of streams it can handle without stuttering. Working at 65% load, the Threadripper scored 404 W/h.

Then the same was done with 50 HD streams fed to Cinegy Multiviewer 21, this time with GPU decoding enabled. The meter reading showed 463 watts per hour. These figures are still not convincing enough as an argument for energy efficiency.

However, it was decided to use the joint capacity of 4 GPUs to its fullest, so one last test was run with 100 feeds decoded by GPUs. And this is exactly where it can be concluded that better GPU utilization introduced in Cinegy Multiviewer 21 is a step to make decoding energy efficient – 705 W/h was the meter reading!

Look at per-stream monthly costs.
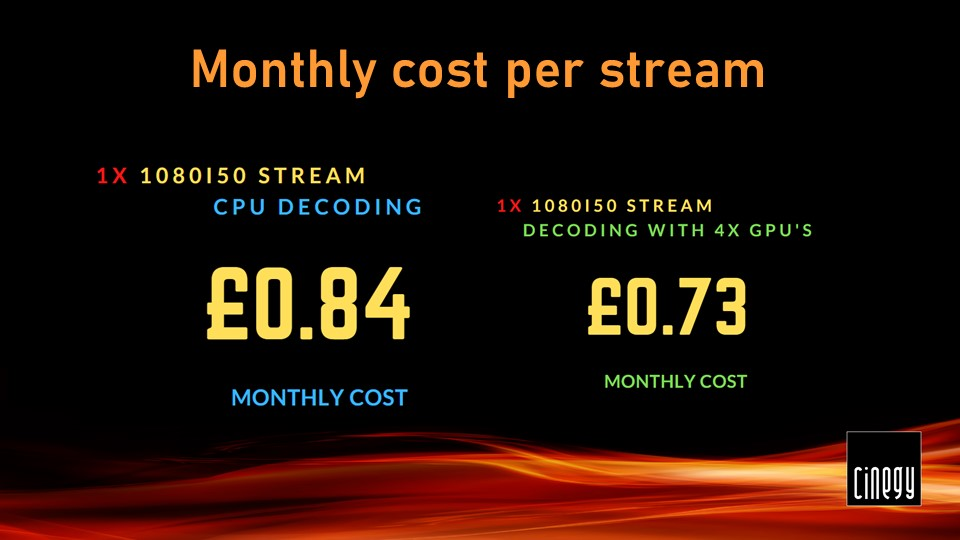
GPU decoding is clearly a way to save you some money, and don’t forget that the Threadripper was only able to decode 50 streams without stuttering, compared to 100 streams decoded by four GPUs.
Now imagine building a machine that can monitor 100 HD streams just with CPU decoding. That would probably require adding another Threadripper 3990X chip to your server.

Not just would it result in doubled power consumption, but also cost you around 4000 pounds in purchase price. The cost of our Threadripper with 4 NVIDIA RTX GPUs setup is roughly 6400 pounds.
Given how low the CPU utilization was with GPU decoding enabled, it’s safe to assume that one might get away with a 24-core chip for a similar server. A 24-core AMD chip of the same generation was chosen to be a fair comparison to Threadripper 3960X. The combined cost of 4x NVIDIA Quadro RTX 4000 boards and an AMD Threadripper 3960X chip would barely hit the price of a 3990X chip on its own and would still be able to comfortably monitor 100 HD feeds.

GPU decoding doesn’t just offer a supreme density, higher cost efficiency, and better performance; it’s also a way to reduce your carbon footprint by using energy-efficient solutions.
Combined Summary
Here’s a combined graph of test results between Cinegy Multiviewer 15 and Cinegy Multiviewer 21 on different hardware.
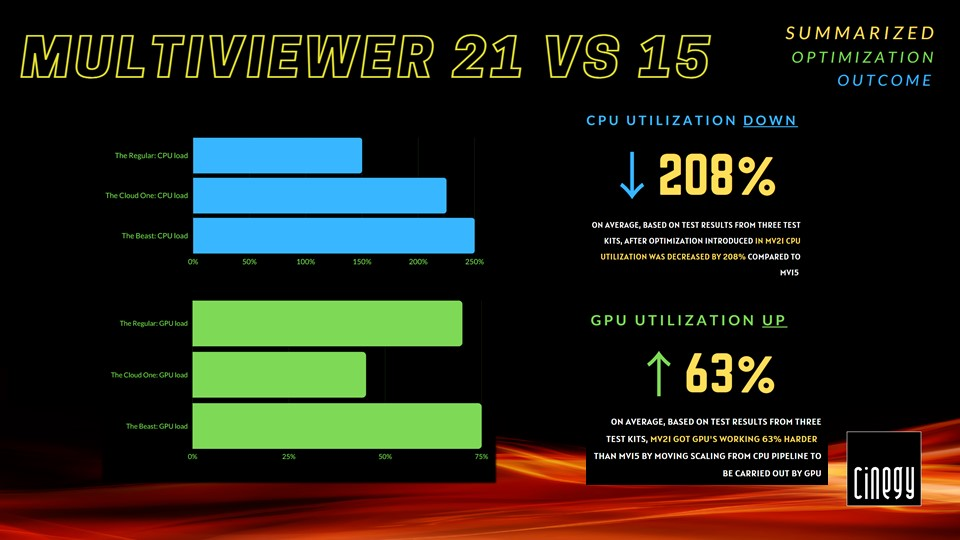
As can be seen with the changes we have introduced, the CPU load has been reduced by more than a factor of 2 across all 3 test kits at the same time.
At the same time, in each of these cases, an amazing improvement was achieved in GPU utilization – no matter if it’s a new RTX 4000, an older entry-level P2200, or a cloud-based T4.
Conclusions
Now is a time for broader conclusions on this entire experiment:
-
GPUs are a good way to breathe some new life into your existing hardware!

Even if your server has a 7-year-old CPU like used in TestKit #1, adding a modern GPU like a brilliant RTX4000 to your setup will cost around 800 pounds but will help to keep your HW delivering valuable functionality for another few years.
-
GPU acceleration is an absolute necessity for cloud deployments as this will drive higher density, better performance, and more cost-efficiency;

CPU-based computing simply can’t offer you the kind of value for money that you get with GPU instances.
-
Even with multiple GPUs working in parallel for maximal density, you get less power consumption at a lower cost.

Cinegy Multiviewer 21 is going to be even better and faster for your monitoring.